
16. Sampling Methods
Sampling Methods in Machine Learning
Sampling Methods
Sampling is a critical process in statistical analysis and machine learning, where a subset of a population or dataset is selected for analysis. Sampling can be broadly categorized into probability sampling and non-probability sampling. Sampling can also occur with or without replacement, an important distinction that defines whether a selected element can be chosen more than once in a single sample.
Probability Sampling
In probability sampling, each member of the population has a known, non-zero probability of being selected. This approach is often preferred for creating representative samples.
-
Simple Random Sampling: Each member of the population has an equal chance of selection. Can be conducted with or without replacement.
-
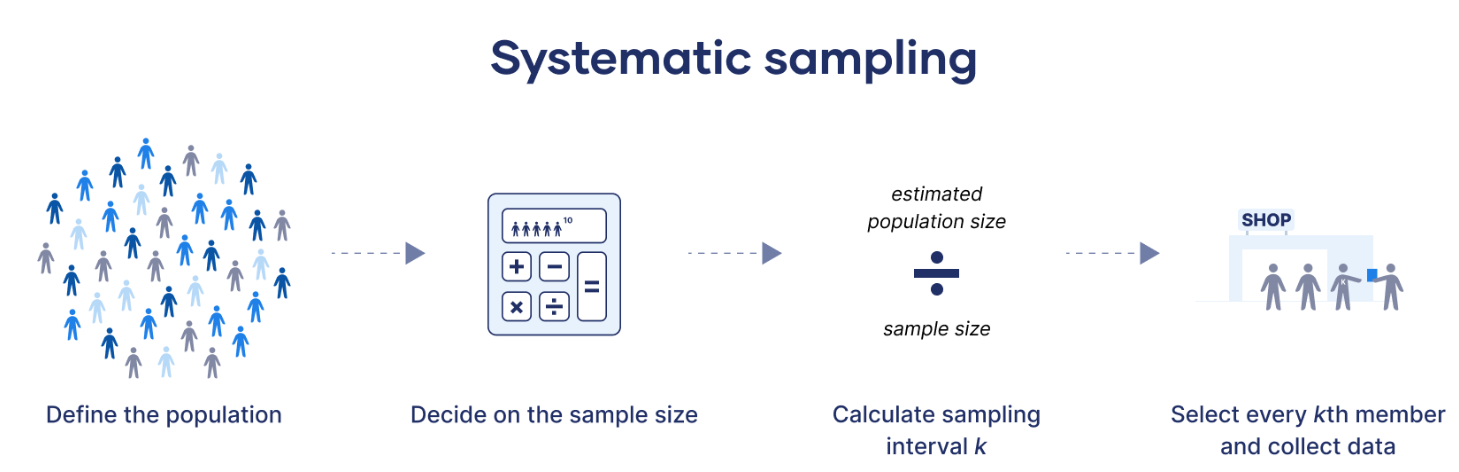
Systematic Sampling: Every $k$-th member is chosen from a list after a random starting point. This method is simple to implement but may introduce bias if the list has patterns.
-
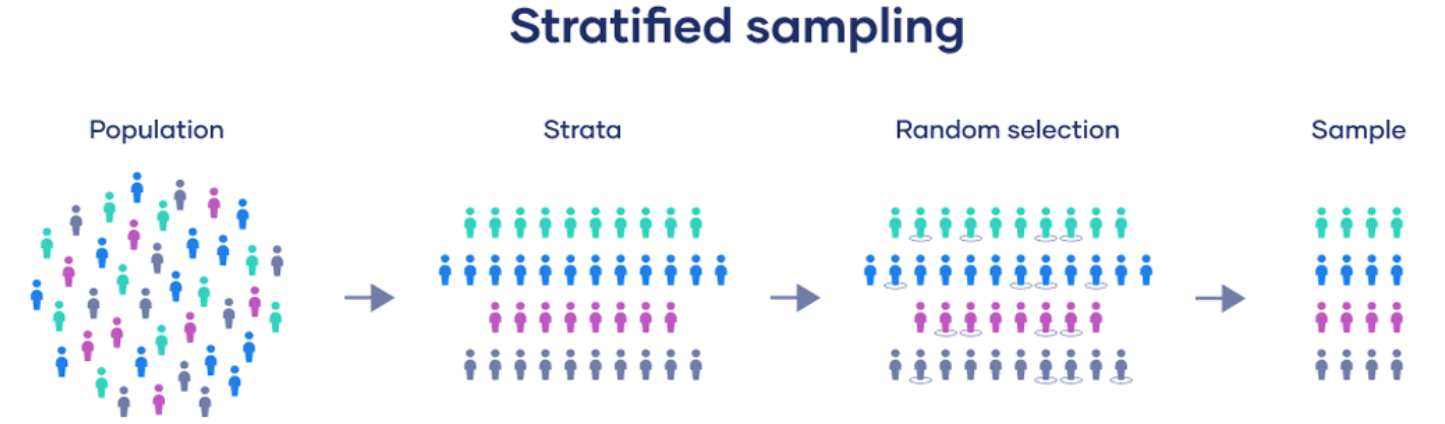
Stratified Sampling: The population is divided into strata (e.g., age groups), and random samples are drawn from each stratum. Ensures representation across key subgroups but requires knowledge of population characteristics.
-
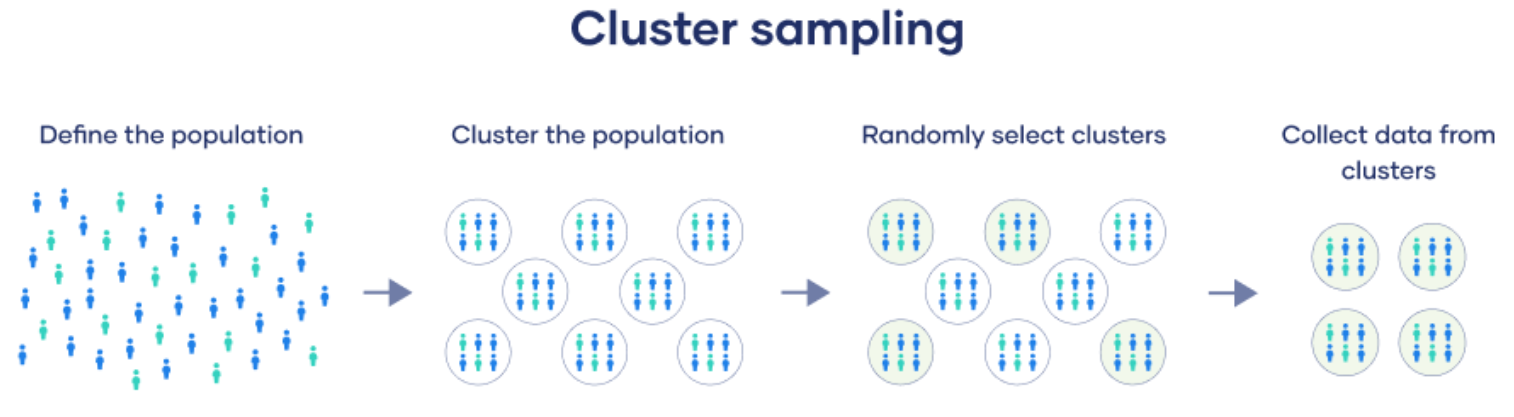
Cluster Sampling: The population is divided into clusters (e.g., geographic regions), and entire clusters are randomly selected. Useful for large, dispersed populations, but clusters may not be homogeneous, impacting representativeness.
-
Multistage Sampling: A combination of the above techniques, often involving cluster sampling at an initial stage, followed by random or stratified sampling within clusters. Complex but effective for large-scale studies.
Non-Probability Sampling
In non-probability sampling, some members of the population have zero chance of selection, often leading to bias.
-
Convenience Sampling: Selection based on ease of access. Inexpensive but may not represent the entire population accurately.
-
Judgmental (or Purposive) Sampling: The researcher selects participants based on their judgment of who would be most informative. Useful for expert opinion but lacks generalizability.
-
Quota Sampling: The sample is designed to reflect specific characteristics of the population but without random selection within groups, which may introduce bias.
-
Snowball Sampling: Participants recruit other participants, useful for hard-to-reach populations but may lead to bias if initial contacts are not representative.

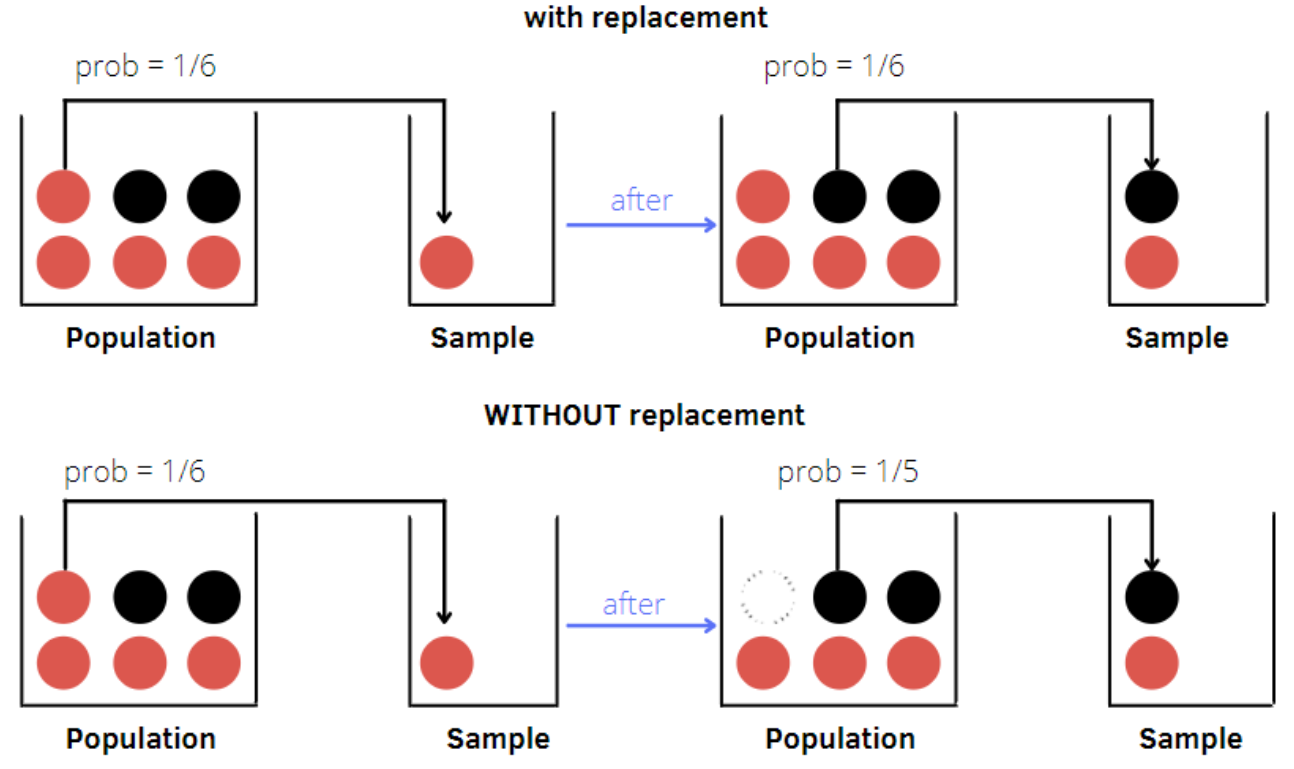
Sampling with and without Replacement
Sampling methods can be performed either with replacement or without replacement:
-
With Replacement: Each selected element is returned to the population, allowing it to be chosen multiple times. This approach is useful in resampling techniques, such as bootstrapping.
-
Without Replacement: Each selected element is removed from the population, preventing it from being selected again in the same sample. This approach ensures a diverse sample without repeated elements.
Feature Randomization and Feature Flagging
Feature Randomization
Feature randomization is a technique often used in ensemble learning methods, particularly in decision tree-based models like Random Forests. In feature randomization, only a subset of features is selected randomly at each split in the decision tree construction. This process has several benefits:
-
Reduces Overfitting: Randomizing features at each split reduces the likelihood that the model becomes overly dependent on any single feature, enhancing generalizability.
-
Increases Model Diversity: By using different subsets of features for each tree, Random Forests can generate diverse decision trees, which helps improve ensemble robustness.
-
Improves Computational Efficiency: Limiting the number of features considered at each split speeds up the model training process, particularly with high-dimensional datasets.
In feature randomization, the commonly used heuristic is to select $k = \sqrt{n}$ features, where $n$ is the total number of features. This choice strikes a balance between model complexity and the need for diversity, allowing each tree to focus on different aspects of the data without becoming too complex.
Feature Flagging
Feature flagging is a technique in software development used to control the release and availability of specific features. In machine learning, it can be used to:
-
Control Experimentation: Enable or disable features dynamically to conduct A/B testing or incremental rollout of new features.
-
Facilitate Model Updates: Implement and test new features without disrupting the main model, allowing for smoother transitions and easy rollback if issues arise.
-
Personalization: Enable specific features for targeted user groups, useful in recommendation systems and personalized applications.
Feature flagging, when applied effectively, can significantly enhance the flexibility and adaptability of machine learning systems.
